- tags: Linux
- 原文连接:Linux Virtual Memory Management
Chapter 2 Describing Physical Memory:描述物理内存
-
独立于平台架构的方式描述内存 — 更好的支持多平台
-
本章包含描述存储器、内存页的结构体(structures)和一些影响 VM 行为的标识位(flags)
-
VM 中普遍(prevlent)认为第一重要(principal)的概念是 NUMA。
-
大型机器中内存访问速度取决于 CPU 到内存的距离。比如一组(bank)内存分配给每一个处理器或者一组内存非常适合靠近的 DMA 设备卡。
-
这里的每组(bank)内存被称为节点(node)并且这个概念在 Linux 中通过 struct pglist_data(typedef pg_data_t) 表示,即使在 UMA 架构下也是如此。每一个节点是一个由 NULL 结尾的链表,通过 pg_data_t->next_node 指向下一个节点。
-
每一个节点都被分割成多个块(block)称为分区(zone)用于表示内存中的范围。分区使用 struct zone_struct(typedef zone_t) 结构体描述,每一个分区都是以下三种类型的一种
- ZONE_DMA 开始 16MB 内存,供 ISA 设备使用
- ZONE_NORMAL 16MB - 896MB,由内核直接映射到线性地址空间的上部区域(将在第四章讨论)
- ZONE_HIGHMEM 896MB - END,剩余不由内核直接映射的系统可用内存, 大部分内核操作都只能使用这种类型的分区,所以这里也是这里也是最关键的性能区域(most performance critical zone)
-
每一个物理页帧(physical page frame)都使用结构体 struct page 表示,所有的结构体都保存在全局数组 mem_map 中,mem_map 通常存储在 ZONE_NORMAL 的开始处;
-
结构体之间的关系
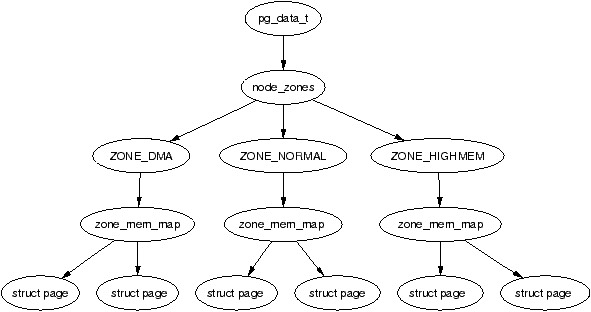
内存节点
Linux 在分配内存页的时候采用 本地节点分配策略(node-local allocation policy) 通过最靠近当前运行 CPU 的节点去分配内存。同时进程也会趋向于采用同一 CPU 运行。
节点的结构体定义在 <linux/memzone.h> 下
typedef struct pglist_data {
// 当前节点包含的分区:ZONE_HIGHMEM,ZONE_NORMAL,ZONE_DMA
zone_t node_zones[MAX_NR_ZONES];
// 定义的顺序决定分配优先采用的分区
zonelist_t node_zonelists[GFP_ZONEMASK+1];
// 当前节点包含的分区数量,1 到 3 之间,不一定全有,比如一个 CPU Bank 可能没有 ZONE_DMA
int nr_zones;
// 节点上每一个物理的帧的页数组的第一个元素(第一页),会在某个地方被全局 mem_map 数组替换
struct page *node_mem_map;
// 位图(bitmap)表示节点中没有内存的“洞(holes)”,仅用在 Sparc 和 Sparc64 架构
unsigned long *valid_addr_bitmap;
// 第五章关于启动内存分配器
struct bootmem_data *bdata;
// 当前节点的起始物理地址
unsigned long node_start_paddr;
// 用于全局 mem_map 设置页偏移量,用于计算全局 mem_map 和当前节点(lmem_map)之间的页数
unsigned long node_start_mapnr;
// 当前分区的总页数
unsigned long node_size;
// 从 0 开始的节点 id
int node_id;
// 指向下一个节点,NULL 表示结尾
struct pglist_data *node_next;
} pg_data_t;
系统中的所有节点都维护在 pgdat_list 中。
分区
用于跟踪信息,如
- 页请用情况
- 可用区域
- 锁,等
定义在 <linux/memzone.h>
typedef struct zone_struct {
// 自旋锁用于保护并发访问
spinlock_t lock;
// 全部可用页数
unsigned long free_pages;
// 分区水印(watermarks)
unsigned long pages_min, pages_low, pages_high;
// 标识位用于告知换页(pageout)守护 kswapd 平衡当前分区(当获取任意水印后则需要进行平衡)
int need_balance;
// 可用区域位图用于其他分配器(buddy allocator)
free_area_t free_area[MAX_ORDER];
// 进程等待页被释放的 Hash table 实现的等待队列,
wait_queue_head_t * wait_table;
// Hash 表中等待队列的数量(2的次方)
unsigned long wait_table_size;
// 用 long 定义上面大小减去二进制对数位的数量
unsigned long wait_table_shift;
// 指向父
struct pglist_data *zone_pgdat;
// 当前分区指向的全局 mem_map 的第一页
struct page *zone_mem_map;
// 同 node_start_paddr
unsigned long zone_start_paddr;
// 同 node_start_mapnr
unsigned long zone_start_mapnr;
// 字符串名字,如 “DMA”, “Norma” or “HighMem”
char *name;
// 当前分区包含的页数
unsigned long size;
} zone_t;
分区水印
当系统可用内存非常少时会唤醒换页守护 kswapd 释放内存页。如果压力过大 kswapd 会进行同步释放内存,有时被称为直接回收(direct-reclaim)路径。
每个分区有三个水印
- pages_low,当阈值达到这个值则唤醒 kswapd 释放内存页
- pages_min,通过 free_area_init_core 根据分区大小页数比(ZoneSizeInPages / 128)初始化,最小 20 页(x86 80K),最大 255 页(x86 1MB ),阈值达到这个值触发 kswapd 同步方式(fashion)工作
- pages_high,不会触发 kswapd 平衡内存页,并使 kswapd 陷入休眠
计算分区大小
PFN(Page Frame Number) 是一个包含物理内存映射的偏移量用于内存页计数,第一个 PFN被系统使用
- min\_low\_pfn 用于定位第一页加载内核镜像的后的开始
- max_fpn 指示系统中最后一个内存页帧
- max_low_pfn 标记 ZONE_NORMAL 结尾,
- 内存少的机器 max_pfn 和 max_low_pfn 一致
通过上面三个值可以直接计算出高区内存的开始和结束。
分区等待队列表
当 IO 在一页内存上开始执行时(page-in or page-out)会进行锁定防止获取到不一致的数据。
- 进程使用页时调用 wait_on_page 加入到一个等待队列
- IO 完成后调用 UnlockPage 解锁
- 唤醒所有等待的进程
每次换页都会有一个等待队列,且代价非常昂贵,通过分离许多队列进行优化,等待队列存在 zone_t 中。
如果一个分区仅有一个等待队列就会产生惊群效应(thundering herd)。为了解决这个问题会有多个等待队列存储在哈希表 zone_t->wait_table 中(极少的哈希碰撞依然会导致不必要的进程被唤醒)。
分区初始化
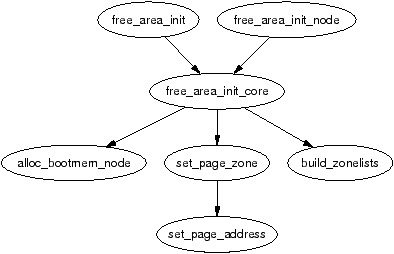
内核页完全初始化后(paging_init)后开始初始化分区,可以预见的是(perdictably)各个平台实现不一致,但是确定(determine)发送给 free_area_init 的参数的逻辑是一致的,支持以下参数
- nid 分区所属节点的逻辑 ID
- pgdat 初始化的所属节点的
pg_data_t,UMA 下则为contig_page_data - pmap 指向分配给节点的本地数组
lmem_map的开始,稍后由free_area_core初始化 - zones_sizes 一个包含内存页中所有分区大小的数组
- zone_start_paddr 第一个分区的起始物理地址
- *zone_holes 包含分区内内存段(memory holes)总大小的数组
free_area_init_core 负责使用相应的信息填充 zone_t 并为节点分配 mem_map 数组。
初始化 mem_map
me_map 会在系统启动中以两种方式(fashions)之一进行创建
- NUMA:当作一个起始于 PAGE_OFFSET ,调用
free_area_init_node初始化这个数组中分配的系统中每一个活跃的节点 - UMA:
free_area_init使用contig_page_data作为当前节点,使用全局mem_map作为当前节点的“本地”mem_map
两个函数的调用关系如下图所示
页
每页物理页帧在系统中都通过 struct page 关联,用于跟踪状态。
声明在 <linux/mm.h> 中
typedef struct page {
// 页可能归属于多个列表,此字段用于存放所属链表的表头(多个),也用于将多个(blocks)空闲的表连接在一起
struct list_head list;
// 用于当文件或设备映射到内存后关联 inode
// 如果页属于文件则指向当前地址空间(address space)
// 如果是匿名页但被设置则说明是 swap 地址空间
struct address_space *mapping;
// 意义取决于页的状态
// 1. 页是文件映射的一部分表示文件的偏移量(offset)
// 2. 页是 swap 缓存的一部分表示 address_space 对 swap 地址空间的偏移量
unsigned long index;
// 作为文件映射一部分的页的 inode 和偏移量的哈希,将共享同一个哈希桶(hash_bucket)的页连接在一起
struct page *next_hash;
// 当前页的引用计数,变成 0 表示可能被释放,否则就被一个或多个进程使用或用于内核 IO 等待
atomic_t count;
// 定义页的状态,见下表
unsigned long flags;
// 用于页替换策略
struct list_head lru;
// 配合 next_hash 实现类似双端链表的操作
struct page **pprev_hash;
// 1. 块设备用于跟踪 buffer_head
// 2. 由进程映射的匿名页如果支持交换文件可能关联一个 buffer_head,如果页必须以底层文件系统定义的大小的块和支持的存储同步则有必要
struct buffer_head * buffers;
#if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
// ZONE_HIGHMEM 的虚拟地址
void *virtual;
#endif /* CONFIG_HIGMEM || WANT_PAGE_VIRTUAL */
} mem_map_t;
映射页到分区
page->zone内核版本 2.4.18 之前struct page通过page->zone引用所属的分区page->flags内核版本 2.4.18 之后通过顶部ZONE_SHIFT(8 in x86) 个位替代page->zone来计算页所属的分区。
映射过程
-
在
mm/page_alloc.c中初始化zone_table33 zone_t *zone_table[MAX_NR_ZONES*MAX_NR_NODES]; 34 EXPORT_SYMBOL(zone_table);MAX_NR_ZONE定义一个内存节点中的最大分区数量MAX_NR_NODES定义最大可存在的内存节点数量EXPORT_SYMBOL()使zone_table可被可加载模块(loadable modules)访问。
这个表将被当作一个多维数组对待。
-
在
free_area_init_core中初始化内存节点中所有的页-
设置分区表(zone table)的值
733 zone_table[nid * MAX_NR_ZONES + j] = zone;nid– 当前内存节点 IDj– 分区(struct zone_t)索引
-
调用
set_page_zone788 set_page_zone(page, nid * MAX_NR_ZONES + j);page分区内被初始的页,所以zone_table的索引存储在页中
-
High Memory
内核支持 High Memory 用于解决内核可使用的地址空间不足的情况(目前 64 位平台下基本上所有内存都可以映射到内核,所以基本不会存在这种情况)。
32 位 x86 系统关于 High Memory 存在两个阈值
- 4GiB:32 位物理地址最大可寻址大小,内核 通过
kmap()临时将内存页从 High Memory 映射到ZONE_NORMAL用于访问 1GiB 到 4GiB 的内存 - 64GiB:Intel 发明的 PAE(Physical Address Extension)允许 32 位系统下使用更多内存,通过增加额外的 4 位用于内存寻址最大可以支持 2 的 36 次方个字节(64GiB)的内存寻址
缺陷
- 理论上 PAE 允许处理器最大可寻址 64GiB,但是由于 Linux 的虚拟地址空间最大仅支持 4GiB,所以进程依然不能使用这么多内存。
- PAE 同时也不允许内核本身使用这么多内存:描述 1GiB 内存需要消耗 11MiB 内核内存(每个
struct page需要在内核虚拟地址空间中(ZONE_NORMAL)消耗 44 字节),16GiB 需要 176MiB,这样会给ZONE_NORMAL造成很大的压力
2.6 中的变更
-
描述内存节点的
pg_data_t- node_start_fpn 替换了
node_start_paddr,用于适配 PAE 架构可以突破 32 位寻址解决通过旧字段无法访问 4GiB 之后的内存节点 - kswapd_wait 用于 kswapd 的新的等待队列替换之前的全局等待队列。2.6 中每一个内存节点都有一个对应的 kswapdN(N 对应内存节点的 ID),同时每一个 kswapd 也通过此字段用于自己的等待队列
- node_start_fpn 替换了
-
node_size字段被以下两个字段替代,引入这一变化主要是认识到节点中可能有 “holes” 导致没有物理内存支持寻址这一事实。- node_present_pages 内存节点中存在的总物理页数
- node_spanned_pages 被当前内存节点寻址的总区域,包括任意可能存在的 “holes”
-
zone_t改为struct zone,同时 LRU 列表由全局改为存储再struct zone中(LRU 用于确定内存页释放或切出的顺序)