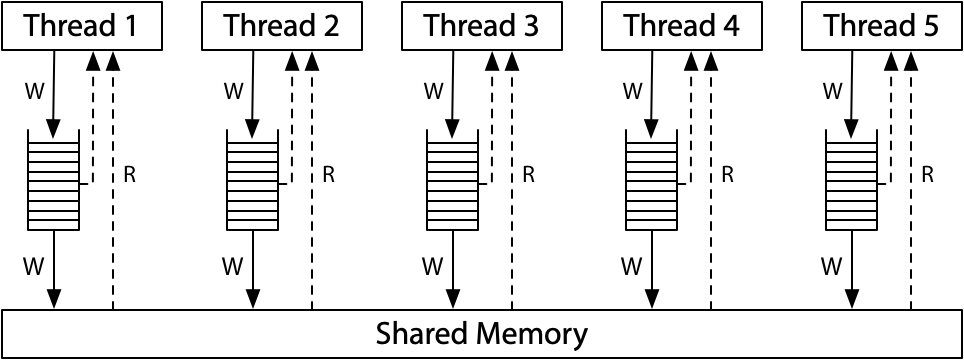
x86 总存储有序(x86 Total Store Order, x86-TSO):所有处理器仍然连接到一个共享内存,但是每个处理器都将对该内存的写入(write)放入到本地写入队列中。处理器继续执行新指令,同时写操作(write)会更新到这个共享内存。一个处理器上的内存读取在查询主内存之前会查询本地写队列,但它看不到其他处理器上的写队列。其效果就是当前处理器比其他处理器会先看到自己的写操作。
重要的是: 所有处理器都保证写入(存储 store)到共享内存的(总)顺序,所以给这个模型起了个名字:总存储有序(Total Store Order,TSO)。
写队列是一个标准的先进先出队列:内存写操作总是以与处理器执行相同顺序的应用于共享内存。
基于以上下面 litmus test 的答案依然是 no ,这种情况与顺序一致性模型结果一致:
Litmus Test: Message Passing
Can this program see r1 = 1, r2 = 0?
// Thread 1 // Thread 2
x = 1 r1 = y
y = 1 r2 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): no.
但其他测试则并不一致区分与顺序一致性的常用例子:
Litmus Test: Write Queue (also called Store Buffer)
Can this program see r1 = 0, r2 = 0?
// Thread 1 // Thread 2
x = 1 y = 1
r1 = y r2 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): yes!
TSO 系统中,线程 1和 2 可能会将它们的写操作排队,然后任何一个写操作进入内存之前从内存中读取,这两个读操作都会看到零。但是任何顺序一致的执行中, x=1 或 y=1 必会有一个首先生效。
如果基于 TSO 系统需要更强的内存排序,可以使用内存屏障。
一旦一个写操作到达主存储器,所有处理器不仅同认同该值存在,而且还认同它相对于来自其他处理器的写操作的先后顺序。考虑一下这个litmus test:
Litmus Test: Independent Reads of Independent Writes (IRIW)
Can this program see r1 = 1, r2 = 0, r3 = 1, r4 = 0?
(Can Threads 3 and 4 see x and y change in different orders?)
// Thread 1 // Thread 2 // Thread 3 // Thread 4
x = 1 y = 1 r1 = x r3 = y
r2 = y r4 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): no.